cgroup
Linux cgroup
cgroups(Control Groups)通过不同的子系统限制了不同的系统资源,每种子系统限制一种资源。每个子系统限制资源的方式都是类似的,就是把相关的一组进程分配到一个控制组中,然后通过树结构(hierarchy)进行管理。每个控制组设有自己的资源控制参数。
默认情况下,系统中,所有进程位于同一个cgroup,就是根,这个cgroup享有所有的系统资源。
通过cgroup文件系统可以建立一个新的cgroup,可以为其分配进程、资源等。
通过mount查看系统中已经挂载的cgroup。cgroup的根目录是以tmpfs的性质进行挂载的,
通过cgroup可以将定额的系统资源(如CPU、内存等)分配给特定的一组进程。cgroup的主要功能包括:
- Resource limitation:资源限制,比如限制内存使用上限
- Prioritization:优先级分配,通过分配CPU时间片数量及硬盘IO带宽大小,来控制进程运行的优先级
- Accounting:资源统计,比如CPU使用时长、内存用量等。
- Control:进程控制,比如挂起进程、恢复执行进程
cgroup子系统
cgroup本身是分层级的,一个根层下面像一棵树一样可以分很多层。每一层的cgroup文件系统目录下都有改成对应的资源配置文件。这些可以配置的文件都是cgroup子系统。
通过lssubsys -m,可以查看cgroup的子系统。在/sys/fs/cgroup下有cgroup的子目录,这些子目录均为cgroup的子系统。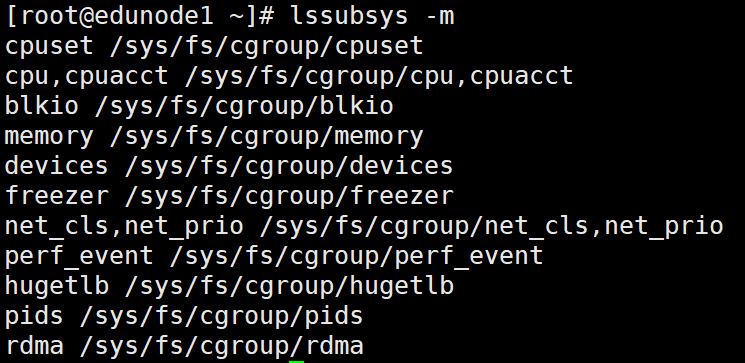
cgroup包含的子系统有:
- cpu:用于控制cgroup中所有进程可以使用的CPU时间片。主要限制进程的cpu使用率
- cpuacct:可以生成cgroups中的进程的cpu使用报告
- cpuset:对于多核cpu,可以为cgroups中的进程分配单独的cpu节点或者内存节点
- memory:可以限制进程的memory使用量
- blkio:可以限制进程的块设备io
- devices:可以控制进程能够访问某些设备。通过提供device whilelist实现的,devices子系统通过在内核对设备访问的时候加入额外的检查实现。devices子系统本身只需要管理好设备访问列表。
- net_cls:可以标记cgroups中进程的网络数据包,然后可以使用tc模块(traffic control)对数据包进行控制,限制网络带宽
- net_prio:用来设计网络流量的优先级,对每个网络接口指定优先级
- freezer:可以挂起或者恢复cgroups中的进程。freezer.state可能读出的值有3种,分贝是FROZEN(已挂起)、THAWED(正常运行、已恢复)、FREEZING(该值代表cgroup中有些进程现在不能被frozen,当这些进程从该cgroup消失时,FREEZING会变成FROZEN)
- ns:可以使不同cgroups下面的进程使用不同的namespaces。ns子系统没有自己的控制文件,而且没有属于自己的状态信息。ns子系统实际上是提供了一种同命名空间的进程聚类的机制。具有相同命名空间的进程会在相同的cgroup分组中。
- hugetlb:主要针对于HugeTLB系统(大页文件系统)进行限制
- perf_event:对cgroup中的进程组进行性能监控
- pids:限制在cgroup中创建的进程数量
- rdma:限制cgroup中使用的rdma(Remot Direct Memory Access)
CPU子系统
用于控制cgroup中所有进程可以使用的CPU时间片,cpu子系统下的cgroup目录中,存在一个cpu.shares的文件,对其写入整数值,可以控制该cgroup获得的时间片。
例如,在两个相同层级的cgroup中,都将cpu.shares设置为1,那么这两个cgroup将会有相同的CPU时间。如果将其中一个cgroup中的cpu.shares设置为2,那么该cgroup中可使用CPU时间是另一个cgroup中可使用CPU时间的两倍。
CPU子系统通过Linux CFS调度器(Completely Fair Scheduler)实现的,CPU子系统调度CPU访问控制有两种模式:CFS(Completely Fair Scheduler)和RTS(Real-Time Scheduler),RTS的方式只有在进程中采用了RTS调度算法时才生效。
cpuacct子系统
cpuacct子系统自动生成cgroup中任务所使用的CPU报告。
- cpuacct.usage:该group及其子group的CPU总使用时间(ns)
- cpuacct.stat:该group及其子group的CPU的用户态和内核态的分别使用时间(ns)
- cpuacct.usage_percpu:该group及其子group的CPU分别使用时间(ns)
cpuset子系统
为cgroup中的任务分配独立的CPU(多核系统中)和内存节点。
- cpuset.cpus:绑定该group的CPU节点,如绑定该进程可以使用0、1、2、6、8这5个CPU,写入文件数据格式是”0-2,6,8”
memory子系统
可以设定cgroup中任务使用的内存限制,并自动生成由哪些任务使用的内存资源报告。memory子系统是通过Linux的resource counter机制实现的。
1 | struct res_counter{ |
在/sys/fs/cgroup/memory下,创建文件夹mkdir test,即创建了一个子cgroup,子cgroup中的文件包含如下: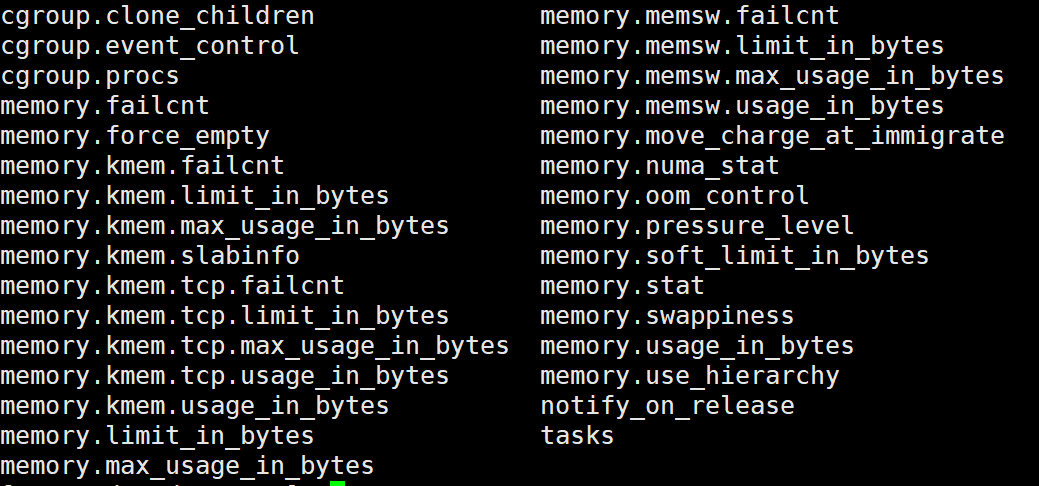
- cgroup.event_control:用于eventfd的接口
- memory.usage_in_bytes:显示当前已用的内存
- memory.limit_in_bytes:设置/显示当前限制的内存额度
- memory.failcnt:显示内存使用量达到限制值的次数
- memory.max_usage_in_bytes:历史内存最大使用量
- memory.soft_limit_in_bytes:设置/显示当前限制的内存软额度
- memory.stat:显示当前cgroup的内存使用情况
- memory.use_hierarchy:设置/显示是否将子cgroup的内存使用情况统计到当前cgroup里面
- memory.force_empty:触发系统立即尽可能的回收当前cgroup中可以回收的内存
- memory.pressure_level:设置内存压力的通知事件,配合cgroup.event_control一起使用
- memory.swappiness:设置和显示当前的swappiness
- memory.move_charge_at_immigrate:设置当进程移动到其他cgroup中时,它所占用的内存是否也随着移动过去
- memory.oom_control:设置/显示oom controls相关的配置
- memory.numa_stat:显示numa相关的内存
设置内存限制
操作cgroup主要有以下3步:
- 创建cgroup
- 设置cgroup参数
- 将进程PID写入cgroup的task
例如设置内存限制步骤如下:
- 创建新的cgroup
cd /sys/fs/cgroup/memory
mkdir test
cd test - 设置memory.limit_in_bytes和memory.memsw.limit_in_bytes
memory.limit_in_bytes用于限制memeory的大小,memory.memsw.limit_in_bytes用于限制memeory+swap的大小。memory.memsw.limit_in_bytes的值应大于等于memory.limit_in_bytescat memory.limit_in_bytes
9223372036854771712
echo 100M > memory.limit_in_bytes
cat memory.limit_in_bytes
104857600
- 将bash设置到tasks中,并创建一个200M的文件
echo $$>tasks
dd if=/dev/zero of=/home/myfile bs=200M count=1
Killed
blkio子系统
为块设备设定输入/输出限制,比如物理设备(磁盘、固态硬盘、USB等)。
该子系统提供了两种控制I/O的方式:
- 基于权重,每个group都可以设置一个数值,根据数值不同,系统分配响应的I/O。以下两个值同一个group中只能存在一个。
- blkio.weight:一个100~1000的数值,全局的权重
- blkio.weight_device:一个100~1000的数值,指定设备的I/O的权重。会覆盖全局的权重值
- 基于速度,每个group都有一个最大的速度,该group的进程I/O不能大于这个速度
- blkio.throttl.read_bps_device:指定该设备上的最大读速度(bytes/s)
- blkio.throttle.read_iops_device:指定该设备上的最大读I/O (I/O read/s);
- blkio.throttle.write_bps_device:指定该设备上最大写速度(bytes/s)
- blkio.throttle.write_iops_device:指定该设备上的最大写IO(I/O read/s)
- blkio.throttle.io_serviced:记录设备I/O操作总数
- blkio.throttle.io_service_bytes:记录设备读取总数
其他参数:
- blkio.reset_stats:对当前文件写入一个整数可重置当前所有统计数据
- blkio.time:指定设备的cgroup控制的I/O访问时间(ms)
- blkio.sectors:指定设备的扇区操作数
- blkio.io_service_time:指定设备的I/O工作时间(ns)
- blkio.io_wait_time:cgroup等待I/O的时间
- blkio.io_merged:被合并的I/O请求
- blkio.io_queued:被cgroup放到队列的I/O请求
hierarchy
一个hierarchy是一组排列在树中的cgroups,树中的每个节点都是一个进程组,系统中的每一个任务都在其中的一个cgroup中,每棵树会关联到多个subsystem。系统中可以有多棵cgroup树。
通过systemd-cgls可已查看Linux cgroup层次结构树。可以显示指定控制组的所有成员进程及其子组和成员。例如:
systemd-cgls / kubepods
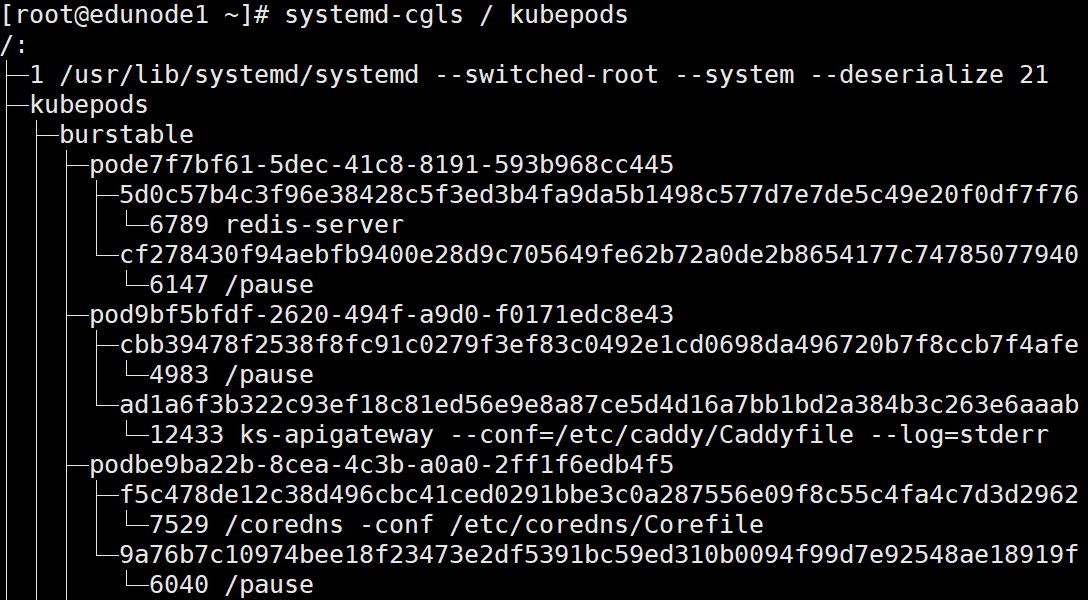
系统阶段,systemd会将它在内核中找到的所有hierarchies挂载到/sys/fs/cgroup下的各个目录。除了/sys/fs/cgroup/systemd目录,其他目录都是对应的子系统。/sys/fs/cgroup/systemd是systemd维护自己使用的,不允许其他程序移动这个目录的内容。
通过将cgroup hierarchy系统绑定到systemd单元树上,systemd可以将资源管理的设置从进程级别移动带应用程序级别。因此,可以使用systemctl指令或者修改systemd单元的配置文件来管理单元相关的资源。
默认情况下,systemd会自动创建slice、scope和service三个层次结构:
- service:systemd基于单元配置文件启动的一个进程或一组进程。服务封装了指定的进程,以便它们可以作为一个集合启动和停止。服务以
name.service的形式被命名。 - scope:一组外部创建的进程。Scopes封装了由任意进程通过fork()函数启动和停止的进程,然后在运行时,由systemd注册这些进行。例如,用户会话、容器和虚拟机被视为作用域。作用域以
name.scope的形式被命名。 - slice:一组分层组织的单元。Slices不包含进程,他们组织了一个层级结构,其中放置了scope和service。实际的进程都包含在scope和service中。在这个层次树中,切片单元的每个名称都对应于层次结构中某个位置的路径。
-字符用作路径组件的分隔符。切片以parent-name.slice的形式被命名。slice是parent的子切片。一个根切片表示为-.slice
服务、范围和切片单元直接映射到cgroup树中的对象。当这些单元被激活时,它们会直接映射到根据单元名称构建的 cgroup路径。例如,ex.service属于test-waldo.slice,会直接映射到cgroup test.slice/test-waldo.slice/ex.service/中。
Subsystem、Hierarchies、Control Groups、Task的关系
一个hierarchy可以附加一个或者多个subsystem(同时参照规则2)。例如cpu子系统和memory子系统(或任意数量的子系统)可以附加到单个层次结构。
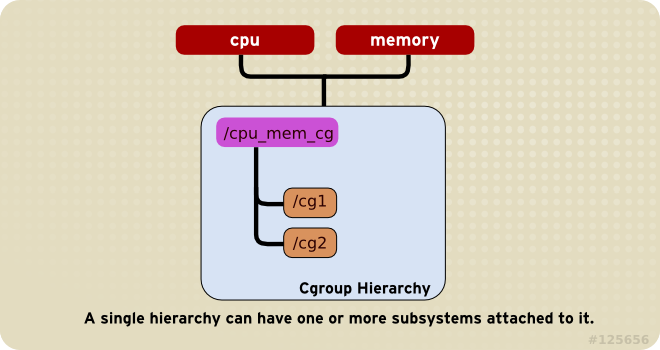
任何single subsystem(例如cpu)都不能附加到多个hierarchy上。如果第二个hierarchy没有其他的subsystem,那么就可以依附,即可以存在两个都仅有cpu依附的hierarchy;如果第二个hierarchy上依附了其他的subsystem,那么就不能依附。如图,图中的编号表示子系统所附的时间序列,因为 Hierarchy B依附了其他系统,所以cpu子系统就不能依附了。
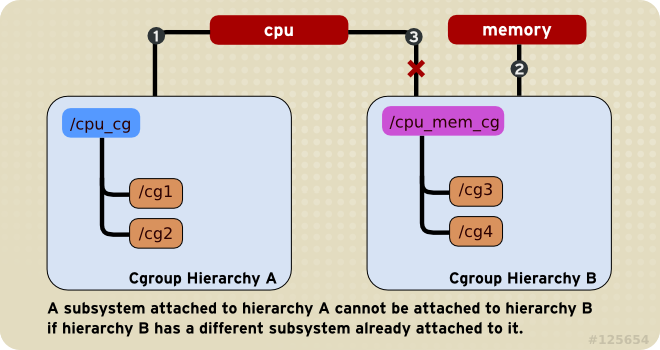
每次在系统上创建新的hierarchy时,系统上所有task(进程)最初都是该层次结构的默认cgroup的成员,该cgroup称为
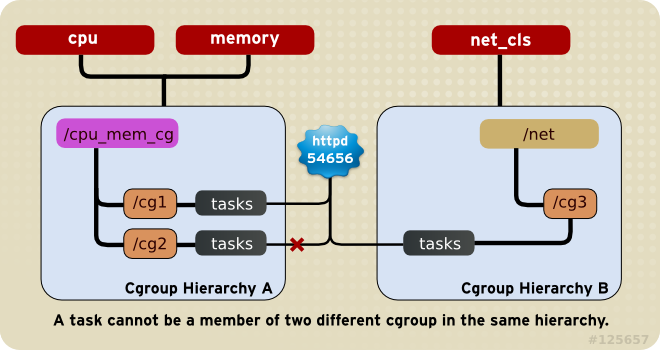
root cgroup,在这个hierarchy中创建的所有cgroup都是这个root cgroup的子节点。对于创建的任何一个hierarchy,系统上每个task都可以是该层次结构中的一个cgroup的成员。一个task可以在多个cgroup中,只要这个task所在的每个cgroup在不同的hierarchy中。如果一个task成为同一个hierarchy中第二个cgroup的成员,那么他就会从该hierarchy中的第一个cgroup中删除。
任何时候,同一个hierarchy的不同cgroup中,不会存在同一个task。
如图,如果cpu和内存子系统连接到名为cpu_mem_cg的hierarchy中,而net_cls子系统连接到名为net的hierarchy中,那么httpd进程可以是cpu_mem_cg中任何一个cgroup的成员,也可以是net中的任何一个cgroup的成员,但其不能同时存在于cpu_mem_cg中的两个cgroup中。
因为当创建第一个hierarchy时,系统上的每个task都至少是一个cgroup(root cgroup)的成员,所以,当使用cgroups时,每个task总是至少在一个cgroup中。
一个进程(task)fork出子进程时,子进程会自动继承父进程的cgroup成员。也可以将子task移动到不同的cgroup中。当fork完成,父子进程就完全独立了。
cgroup1和cgroup2
当前kernel中允许cgroup v1版本和v2版本共存。
Cgroup v2将多hierarchy的方式变成了unified hierarchy,并将所有的controller挂载到一个unified hierarchy。
主要改进:
- Cgroups v2 中所有的controller都会被挂载到一个unified hierarchy下,不在存在像v1中允许不同的controller挂载到不同的hierarchy的情况
- Process只能绑定到cgroup的根(
/)目录和cgroup目录树中的叶子节点 - 通过cgroup.controllers和cgroup.subtree_control指定哪些controller可以被使用
- v1版本中的task文件和cpuset controller中的cgroup.clone_children文件被移除
- 当cgroup为空时的通知机制得到改进,通过cgroup.events文件通知